

How to Reduce Your Cloud Spend without Sacrificing Reliability



Abby Costin
July 28, 2025
Save money on cross-zone traffic in AWS with Kubernetes
Spreading workloads across multiple AZs is a foundational best practice for applications that need high availability and resilience against isolated failures. However, in AWS, this feature comes with a cost: every byte of data that traverses the boundary of an AZ incurs a charge (at the time of publishing they are charging approximately $0.01 per gigabyte). Cross zone traffic doesn’t become a huge concern until you’re running Kubernetes at scale in multi-zone environments. Kubernetes's native load balancing means these inter-zone data transfers can quickly snowball into a significant and unpredictable operational expense with substantial financial implications.
To give a concrete example: for a three-zone Kubernetes cluster in AWS, at current prices, every GB/s of traffic can translate to $210,000 per year in cross-zone spend. These charges can add up quickly!
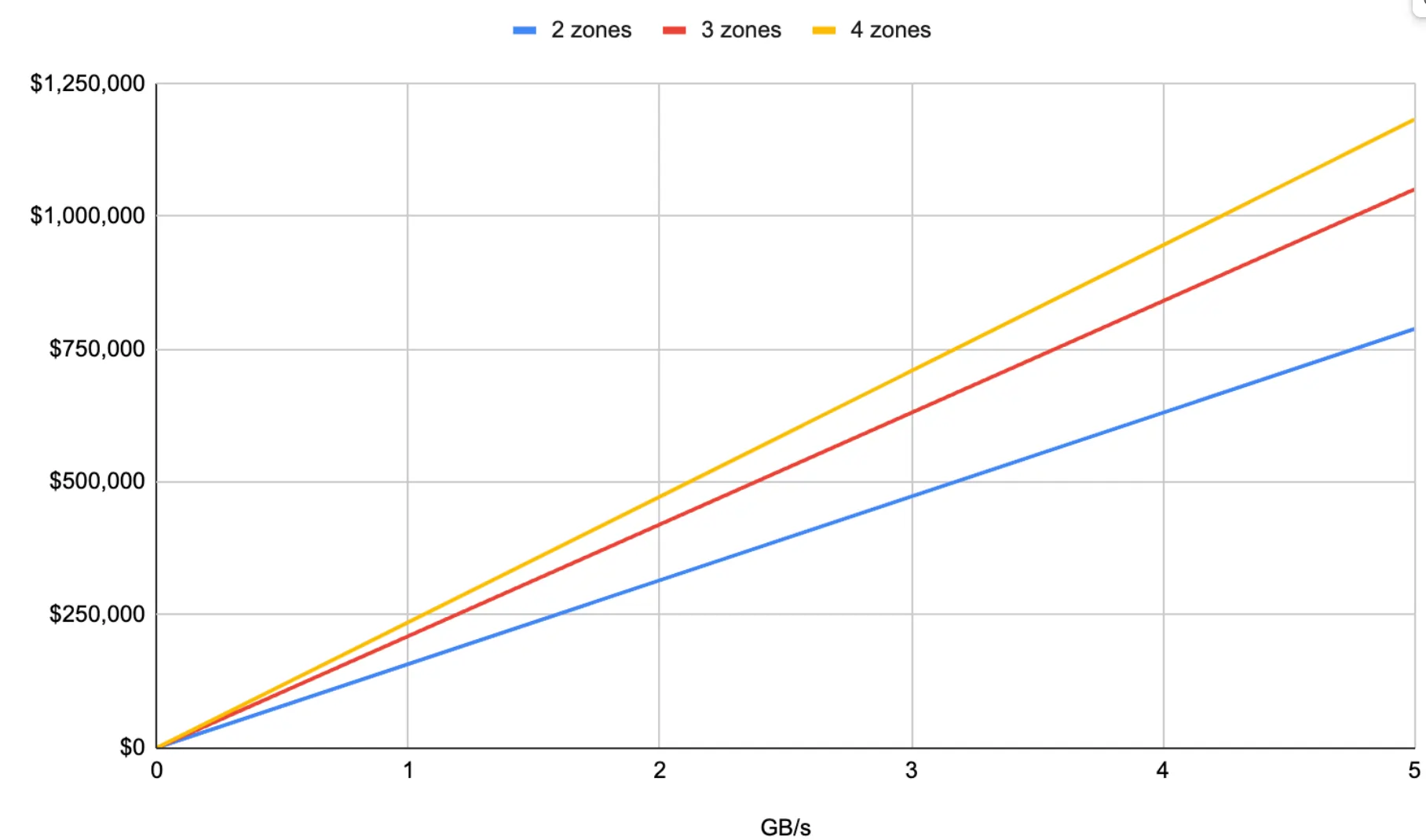
Beyond the bill, organizations also grapple with a lack of visibility and control. Without monitoring in place, it’s easy to land in a situation where your bill skyrockets, but you have no idea which workload caused it or which team to talk to about it.
Ensuring Application Reliability
The key to mitigating these costs without sacrificing the high availability that multi-AZ deployments provide lies in more context-aware traffic management. Linkerd’s High Availability Zonal Load Balancing (HAZL), a powerful feature available in the enterprise version, was designed to meet this need. This feature keeps all traffic within the same zone when conditions are stable but will dynamically send traffic to other availability zones when necessary to preserve overall reliability (and it works for cross-cluster traffic as well as in-cluster traffic). As a system is failing, this feature will ease traffic into other zones as the failure escalates, then reduce it once the failure subsides to keep the success rate at almost 100% (source). With the Enterprise distribution of Linkerd, Imagine Learning is on track to reduce regional data transfer networking costs by at least 40%.
How does HAZL work?
The HAZL feature is based on a simple but effective load metric, using latency × request rate to gauge the saturation of each pod. The feature uses two configurable thresholds to manage traffic: when the load per pod exceeds the upper threshold, HAZL dynamically expands its pool of available endpoints to include pods from other zones, accepting some cross-zone cost in return for preserving functionality. It keeps these non-local endpoints in the pool until the load falls below its lower threshold, at which point it removes the non-local endpoints from the pool, using only the local endpoints to lower costs. This dynamic switching preserves both reliability during stress and cost-effective locality during normal operation.
The graph below demonstrates the power of HAZL in action on a 3-zone EKS cluster.The left side of the graph shows the view before HAZL is enabled. As you can see, about 2/3rds of the traffic is sent across zone boundaries. This is exactly what we would expect with a stock Kubernetes setup where traffic is distributed evenly across zones, and while we’ve achieved reliability, we’re also paying for the cross-zone cost.
Once HAZL is enabled (right side of the graph), cross-zone traffic (and costs) drops to zero, and all traffic now remains in-zone. And most importantly, if a failure were to happen in one zone, HAZL would automatically re-allow cross-zone traffic until the failure was resolved, preserving the very reliability that is the purpose of multi-zone clusters in the first place.

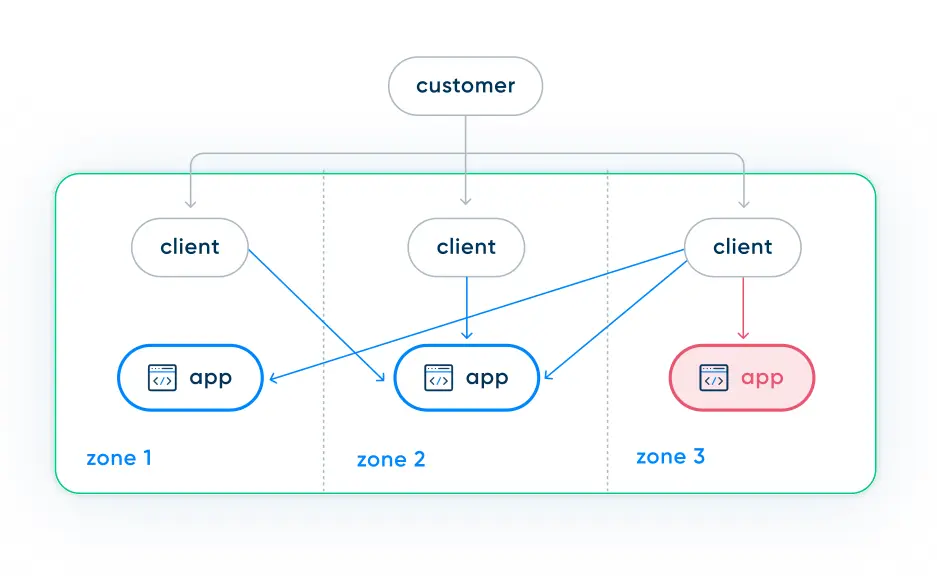
TAR comes with a significant drawback that can compromise application reliability. It operates in an "all or nothing" fashion, meaning once you enable TAR, traffic cannot cross zones at all. This is not an issue if the application is healthy and everything is working as it should. But when a single zone experiences problems (such as pod failures, increased latency, or uneven traffic distribution), TAR prevents requests in that struggling zone from reaching healthy pods in other zones. This means even though there are healthy pods in other zones, the requests will never be routed to them. If requests never reach a healthy pod, the application will show a request error, and those accessing the application will experience downtime.
Conclusion
Linkerd is the only service mesh that offers High Availability Zonal Load Balancing. This feature was designed to help organizations with multi-zone environments:
- Cut cloud spend by eliminating cross-zone traffic both within and across cluster boundaries;
- Improve system reliability by distributing traffic to additional zones as the system comes under stress;
- Prevent failures before they happen by quickly reacting to increases in latency before the system begins to fail.
Preserve zone affinity for cross-cluster calls, allowing for cost reduction in multi-cluster environments.
Try Buoyant Enterprise for Linkerd for free.
Frequently Asked Questions
How significant can cross-AZ traffic costs be for a microservices application?
For high-traffic applications running with a large number of microservices, cross-AZ traffic costs can quickly become substantial and unpredictable, often constituting a hidden but significant portion of an organization's overall AWS bill. Learn how Imagine Learning saved 40 % on networking costs with Linkerd.
Is High Availability Zonal Load-balancing (HAZL) available for open source Linkerd?
HAZL is an enterprise-only feature available in Buoyant Enterprise for Linkerd.
Can Linkerd optimize cloud spend for GCP and Azure?
Linkerd’s HAZL can help manage traffic in any multi-zone cluster. At the time of this writing, Amazon and Google both charge for cross-zone traffic, but Microsoft does not (way to go, Microsoft!) so in Azure clusters, you may see improved latency but not lowered costs.
Does Istio offer any features that compare to the cloud cost optimization capabilities of Linkerd?
No.


