

Service Level Objectives are a hot topic in the world of software reliability. SLOs are usually thought of as a way to balance risk vs. reward for a given application. Should we ship a new feature for this service, even though we might risk an outage?
But for Kubernetes adopters, SLOs can provide something more: a consistent, uniform way to measure the health of every application in their cluster, in a way that requires little history or context about any particular app. Seen in this light, SLOs help platform owners move beyond raw success rates and latencies to understanding the state of their platform in a universal way: what’s on fire, and where do I need to focus my time and energy right now? This shift can be a huge boon for platform owners, especially as the number of applications on the platform grows.
Before we get into the details, let’s define SLOs and how they work.
An SLO combines a metric for a service with an objective, or goal, and a time period. For example, “the success rate for FooService should be at least 99.5% when measured on a rolling seven-day period” is an SLO. In SLO terms, the metric is called the service level indicator or SLI.
Defining an SLO is just a matter of choosing those three parameters—the SLI, the goal, and the time period. Once defined, you can start the process of calculating the current error budget, which is the salient output of the SLO. We’ll see what this error budget means and how to use it below.
The biggest difference between an SLO and a metric is that an SLO provides a judgment. A metric is just a metric: by itself, it doesn’t tell you whether it’s good or bad. If FooService has a 98% success rate, is that good? If it drops to 97.5%, should we panic? Without further context, who knows.
With an SLO, however, we can judge whether things are good or bad: are we meeting our objective, and if so, by how much? This judgment is captured by the error budget. Crucially, it is independent of both the service and the metric—it doesn’t matter what metric you’re using or what the service does, the error budget works exactly the same. This independence is key to understanding the value of SLOs in the platform context.
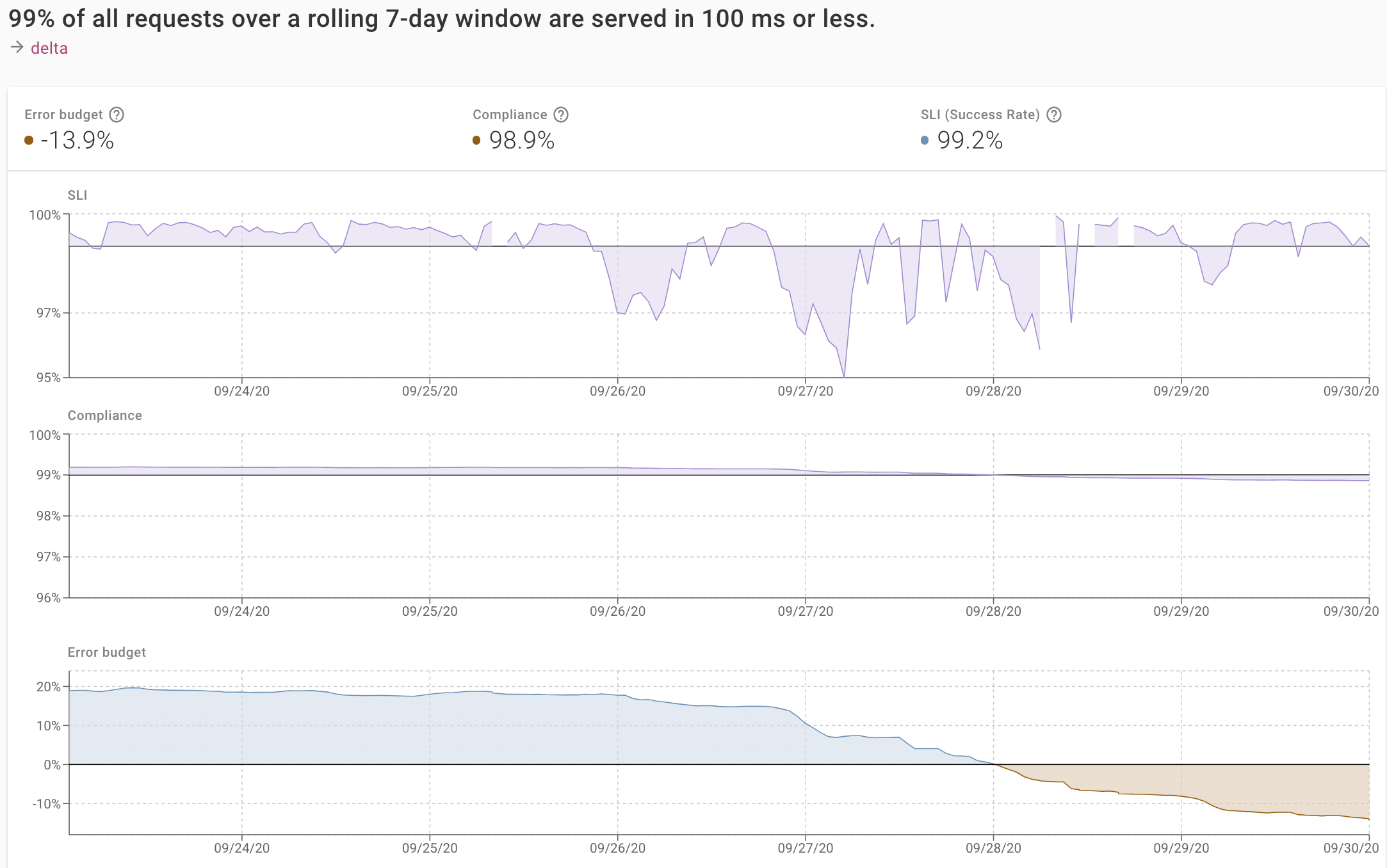
SLOs work by computing an error budget, which measures how far the metric is from the objective when measured over the time period. For example, if your SLO is a 99% success rate over a 7-day rolling window, and your success rate over the past 7 days is 99.75%, then your error budget is 75%.
Note that an error budget can never exceed 100%, but it can go negative!
The error budget tells you exactly how well you’re doing relative to your goal. And since it’s independent of the service and the SLI, the error budget also allows you to compare services. By looking at the error budgets across all services, and their changes over time, platform owners can get a universal measure of the health of their applications—again, independent of what those services actually do.
SLOs are particularly useful in Kubernetes, where applications are broken into dozens or hundreds of services. This is because SLOs universality allow platform owners to move beyond raw metrics and make value judgments about the health of components running on their platform but don’t own directly.
Let’s revisit our example from above: a team deploys a service on your Kubernetes cluster, and it currently has a success rate of 98%. As you watch, it drops to 97.5%. Should you ignore this? Should you panic and alert the team? Without more context, you simply can’t know. Now multiply that dilemma by the hundreds of services on the cluster. Even if you could track the changes, knowing what to do with them is unclear.
SLOs give us a solution to this metric overload. By defining the expectation for these metrics and encoding them as SLOs, you can calculate error budgets. And looking at error budgets across SLOs gives you actionable data: you can see which services are meeting their expectations, which ones aren’t; which ones are trending up and which ones are trending down. Switching from looking at metrics to looking at SLOs allows you to compare services and even sort them by how much they’re on fire.
.png)
If SLOs are so great, why isn’t everyone doing them? Unfortunately, there are still some real impediments to effectively using SLOs on Kubernetes, including:
Happily, the first part is easily solved today: Linkerd, an ultralight service mesh for Kubernetes, can provide a consistent and uniform layer of “golden metrics” (success rates, request rates, and latencies) across every HTTP or gRPC service running on your cluster. You can install Linkerd on your cluster with zero config in around five minutes and immediately get these metrics. From these metrics, you can then compute SLO data. (We’re working on a how-to guide for calculating SLOs with Linkerd and Prometheus, so stay tuned for that!)
Alternatively, if you don’t want to create and manage your SLOs manually, you can use a tool like Buoyant Cloud, which allows you to set up SLOs for Kubernetes with the click of a button. Buoyant Cloud makes it trivial to create and track SLOs across any number of clusters and workloads, to rapidly identify which services are in danger of violating their objective, and to share this data with other people on your team.
Whichever route you go, SLOs are a great way of moving beyond raw metrics and understanding the state of the applications on your platform in a universal way. This is the key to building a stable and reliable platform and to prioritizing your time and energy effectively and efficiently.
Buoyant is the creator of Linkerd and of Buoyant Cloud, the best way to run Linkerd in mission-critical environments. Today, Buoyant helps companies around the world adopt Linkerd, and provides commercial support for Linkerd as well as training and services. If you’re interested in adopting Linkerd, don’t hesitate to reach out!
.svg)
